[Kafka]카프카 설치, 실행
이 글은 카프카, 데이터 플랫폼의 최강자 고승범/공용준 님의 책을 공부하며
정리하는 글입니다.
[Kafka]카프카 설치하기
Kafka version: kafka_2.11-1.1.0 (scala 2.11 지원)
OS: ubuntu 16.04 LTS
특이사항: 주키퍼(3대))와 카프카(3대)는 모두 동일 한 노드에 설치(테스트 목적)
주키퍼 설치 디렉토리: usr/local
카프카 설치 디렉토리: home/username(각자)
카프카 다운로드
$ wget https://archive.apache.org/dist/kafka/1.1.0/kafka_2.11-1.1.0.tgz$ tar zxf kafka_2.11-1.1.0.tgz$ ln -s kafka_2.11-1.1.0 kafka$ ls -al kafka // 심볼릭 링크 확인
카프카 환경설정
서버별 브로커(카프카 설치 애플리케이션) 아이디
카프카 저장 디렉토리
주키퍼 정보
아래는 서버별 브로커 아이디 준비, 매칭된 정보는 기억 후 카프카 환경 설정 수정 시 사용
| 호스트 네임 | 브로커 아이디 |
|---|---|
| zookeeper-01 | broker.id=1 |
| zookeeper-02 | broker.id=2 |
| zookeeper-03 | broker.id=3 |
카프카 디렉토리 만들기
이 예제에서는 디렉토리를 두개 생성한다(data1, data2)
원래는 하나의 머신에 가진 디스크 수 만큼 들어서 분산저장 목적을 두기 때문이다.
각 디스크별로 I/O를 분산할 수 있기 때문이다.
이 예제에서는 디스크가 분리되어 있지는 않지만 분산저장을 목적으로 한다.
$ mkdir -p data1, data2- 카프카 구성 인스턴스에 동일한 경로에 동일한 폴더명(data1, data2)를 생성
카프카 환경설정 알고가기(1)

앙상블(주키퍼 3대 서버)는 모두 동일한 정보를 가지고 있음. 그림처럼 카프카 환경설정 파일에서 주키퍼 정보 입력 시 주키퍼 서버 3대 중 ‘임의의 하나’ 만 입력해도 문제가 없다. 다만 굉장히 위험한 설정이므로 주키퍼 정보를 모두 등록하자.
모든 카프카 클러스어 환경설정 파일에서 오로지 하나의 정보만 주었더니 주키퍼 서버가 다운되었다.
카프카 클러스터 장애상황 발생. 그러나 앙상블 전체는 서버 3대로 구성되었고 과반수 정책으로 주키퍼 시스템은 돌아간다. 그러나 카프카 환경설정에서 주키퍼 서버 하나만 입력했기 때문에 카프카 클러스터는 장애가 발생했다
- 결론: 주키퍼 정보를 입력할 때는 주키퍼 앙상블 서버 리스트를 모두 입력하자
카프카 환경설정 알고가기(2)
핵심은 설정을 변경해 하나의 주키퍼 앙상블 세트를 여러 개의 애플리케이션에서 공용으로 사용하게 해야한다. 주키퍼:카프카 1:1 매칭도 때에 따라서 괜찮지만 공용으로 세팅하는 것이 효율적.
n개의 카프카가 주키퍼 하나에 맞추어지고 동일한 지노드를 사용할 경우 데이터 충돌이 발생.
아래 처럼 최상위 경로(/)에 하위 노드로 지노드를 생성한다.
(1) 은 하나의 주키퍼 앙상블 세트를 두 개의 카프카 클러스터가 사용하기 위함
(2) 는 peter-kafka라는 지노드를 공통으로 사용할 수 있도록 지노드를 생성하고, 하위 지노드로 01, 02와 같이 지노드를 생성해 사용할 수 있다.

- (2)그림을 보면 최상위 경로(/)에 하위 노드로 지노드(peter-kafka)를 생성하고 공통으로 사용할 수 있도록 지노드를 생성하고, 하위 지노드로 01,02와 같이 지노드를 생성해 사용할 수 있다.
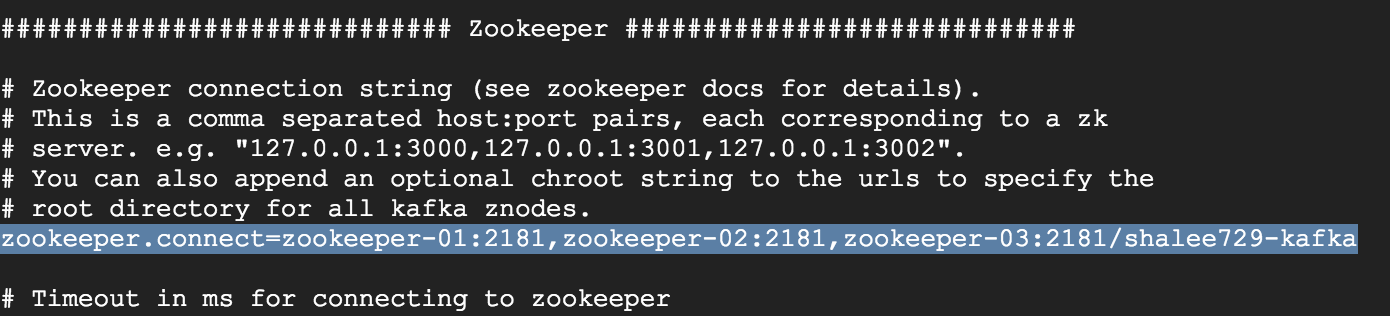
카프카 환경설정(server.properties)
$ cd /home/호스트명/kafka/config$ vi server.properties- kafka 3대 다른 작업
- broker.id=0 부분 수정
- 카프카 호스트 이름과 broker.id를 매핑한 숫자로 변경 ex) broker.id = x

- kafka 3대 공통 작업
- (1)디렉토리 수정
- 디스크 구성이 하나인 경우는 /data1 하나 입력이나 분산저장(분리 디스크라고 생각)을 목표로 아래와 같이 두 개의 폴더를 준비함

- (2)지노드 설정
- 주키퍼의 최상위가 아닌 별도의 지노드를 이와같이 사용하는 경우 브로커가 시작할 때, 해당 지노드가 주키퍼에 없다면 자동으로 지노드를 생성한다.
- kafka 3대 다른 작업
그 외의 옵션들에 대해서는 추후 정리하여 포스팅 합니다 p87
카프카 실행하기
이제 모든 설정이 끝났다. 카프카를 실행해보자.
- 3대의 서버의 주키퍼를 띄우고 -> 3대 카프카를 띄웁니다.
- 주키퍼 실행
$ /home/호스트명/zookeeper/bin/zkServer.sh start
- 주키퍼 정지
$ /home/호스트명/zookeeper/bin/zkServer.sh stop
- 카프카 실행(실행명령어 + 카프카 환경 설정 파일을 옵션으로 줌)
$ /home/호스트명/kafka/bin/kafka-server-start.sh /home/호스트명/kafka/config/server.properties(포그라운드 실행)$ /home/호스트명/kafka/bin/kafka-server-start.sh -daemon /home/호스트명/kafka/config/server.properties
- 카프카 중지
control + c (포그라운드 실행시)$ /home/호스트명/kafka/bin/kafka-server-stop.sh -daemon /home/호스트명/kafka/config/server.properties(백그라운드 중지 명령어)
참고: 카프카, 데이터 플랫폼의 최강자
