[Spark_1]Spark란? RDD란?
in Data on 패스트캠퍼스-데엔스1기
[Spark_1]Spark란? RDD란?
Spark와 RDD를 알아보자
- Apache Spark
- RDD(Resilient Distributed Dataset)
탄력적이면서 분산된 데이터 셋 = List - Scala Interface
- 현재는 RDD의 비중이 높음 다만 앞으로는 DataSet, DataFrame 쪽으로 무게가 실릴 것.
- RDD(Resilient Distributed Dataset)
- Apache Spark 확장 프로젝트
- Spark SQL: Hive와 비슷하게 SQL로 데이터 분석
- Spark Streaming: 실시간 분석
- MLlib: 머신러닝 라이브러리
- GraphX: 페이지랭크같은 그래프 분석
- RDD(Resilient Distributed Datasets)
- RDD공식문서
- 클러스터 전체에서 공유되는 리스트, 메모리상에 올라가있음. (메모리 부족한 경우, 디스크에 spill)
- interface는 List와 거의 동일함
- map, reduce, count, filter, join 등 다양한 작업 가능
- 작업을 병렬적으로 처리
- 여러 작업을 설정해두고, 결과를 얻을 때 lazy하게 계산
- 만약에 20TB 이상의 데이터가 있다. load 등 작업 하나 하는데만 시간이 큼
- 실제 작업정보만 가지고 있다가. 미룰 수 없는 작업이 왔을 때 수행 = Actions
- List와 RDD차이?
- PC한대의 메모리로 처리할 수 있는 만큼만 처리
- RDD는 PC메모리를 넘어서는 양이라도 처리가 가능 -> 영속화 캐싱기능도 있음 (메모리를 넘는 자료 처리가 가능하다는 것은 정보만 가지고 있다가 실제 처리할 때 던짐)
- RDD 특징
- Transformation
- Actions
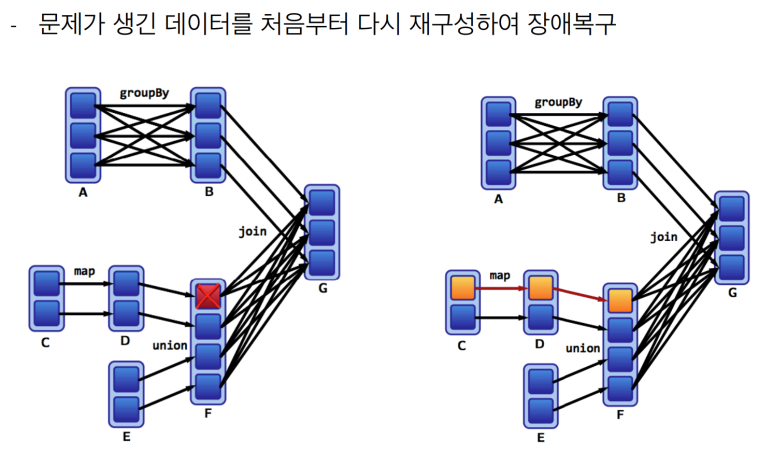
- Lineage : 클러스터 중 일부의 고장으로 실패하더라도, Lineage를 통해 데이터 복구
- Lazy Execution: Transformation에서는 계산을 수행하지않고, Action이 수행되는 시점에 데이터를 읽어들여서 계산을 시작함.
- Lineage
- 여기서 하둡, 맵리듀스와 차이: c1, c2, c3 에서 c3에서 문제가 생기면 다시 계산
- computing 비용때문에 재계산 문제시에 특정 작업단계에서 임시파일로 저장하는 것을 고려하기도 함.
RDD 테스트
버전 정보
Java version 1.8
//Hadoop version: 3.0
Spark version: 2.3
Scala version: 2.11.12
//Python version: 3.6.4
구동
터미널, $spark-shell
val a = List(1,2,3,4,5,6)
//예제, a는 결과를 바로 주지않아. action동작이 들어갈 때 실행.
scala> val b = List(1,2,3,4,5)
b: List[Int] = List(1, 2, 3, 4, 5)
scala> b
res7: List[Int] = List(1, 2, 3, 4, 5)
scala> a
res8: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at makeRDD at <console>:24
scala> a.collect
res9: Array[Int] = Array(1, 2, 3, 4, 5, 6)
scala> b.filter(_<3)
res10: List[Int] = List(1, 2)
scala> a.filter(_<3)
res11: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[2] at filter at <console>:26
//큰 rdd로 체감해보자
scala> val c = sc.makeRDD(0 to 1000000000)
c: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[3] at makeRDD at <console>:24
//선언만 하면 10억개인데 바로 나옴. 즉 메타정보만 가지고 있는 것.
//count하면 시간이 걸림. action이기 때문에 시간이 좀 걸림
scala> c.count
res12: Long = 1000000001
//마찬가지로 action이 없이 메타정보만 가짐
scala> val c2 = c.map(_ * 2)
c2: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[4] at map at <console>:25
scala> val c3 = c2.filter(_ < 10000)
c3: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[5] at filter at <console>:25
//실제 action
scala> c3.count
res13: Long = 5000
